2022-11-13
#seastar
Seastar 中提供了两种协议栈:
其中 native stack 是 seastar 自己实现的一套协议栈, 一般是和 DPDK 配合使用; 而 posix stack 则是传统的内核协议栈; 由于我并不了解 DPDK, 暂时也没有学习/使用的需要, 所以目前还是先关注 posix stack 的实现(只关注 TCP, unix socket/UDP/SCTP 暂时不管), 以及 seastar 是如何抽象 network stack 这个概念从而统一 native stack 和 posix stack 二者的.
为了统一 native stack 与 posix stack, seastar net 模块中抽象除了如下实体:
socket: 可以视作调用了 socket(2)
但是还没有 connect(2) 的 fd, 通过它我们可以发起网络连接得到
connected_socketconnected_socket: 一个处于连接状态的 TCP/SCTP
全双工流server_socket : TCP/SCTP 监听描述符, 等待
accept(2) 新的网络连接udp_channel: udp 管道, 用于读写数据udp_datagram: udp 数据报network_stack:This class is responsible for establishing a connection between two endpoints. It allows for the connection attempt to be canceled.
socket 接口定义也很简单, 最主要的就是提供 connect
接口用于发起网络连接(所以也被称为 client socket, 和 server socket
对应)以及 shutdown 接口关闭网络连接:
class socket_impl {
public:
virtual ~socket_impl() {}
virtual future<connected_socket> connect(socket_address sa, socket_address local, transport proto = transport::TCP) = 0;
virtual void set_reuseaddr(bool reuseaddr) = 0;
virtual bool get_reuseaddr() const = 0;
virtual void shutdown() = 0;
};通过调用 socket 的 connect 方法, 就得到了
connected_socket, 这是一个处于连接状态的 socket,
也就是一个全双工的流, 那么最重要的就是读、写数据,
以及关闭连接(读端和写端可以分别关闭, 就像 shutdown(2)
那样)
此外它还提供了一些获取和设置 socket
属性的功能(常见的属性提供了专门的函数, 其他的则可以用
get_sokopt 和 set_sockopt 方法, 这俩其实就是
getsockopt(2)、setsockopt(2) 的简单
wrapper):
class connected_socket_impl {
public:
virtual ~connected_socket_impl() {}
virtual data_source source() = 0;
virtual data_source source(connected_socket_input_stream_config csisc);
virtual data_sink sink() = 0;
virtual void shutdown_input() = 0;
virtual void shutdown_output() = 0;
virtual void set_nodelay(bool nodelay) = 0;
virtual bool get_nodelay() const = 0;
virtual void set_keepalive(bool keepalive) = 0;
virtual bool get_keepalive() const = 0;
virtual void set_keepalive_parameters(const keepalive_params&) = 0;
virtual keepalive_params get_keepalive_parameters() const = 0;
virtual void set_sockopt(int level, int optname, const void* data, size_t len) = 0;
virtual int get_sockopt(int level, int optname, void* data, size_t len) const = 0;
virtual socket_address local_address() const noexcept = 0;
};server_socket 其实就是一个监听描述符,
最重要的功能当然就是接受新的连接:
class server_socket_impl {
public:
virtual ~server_socket_impl() {}
virtual future<accept_result> accept() = 0;
virtual void abort_accept() = 0;
virtual socket_address local_address() const = 0;
};
struct accept_result {
connected_socket connection;
socket_address remote_address;
};network_stack 则是对整个网络协议栈的抽象,
实际也就是提供了几个常用的函数, listen
、connect、socket、make_udp_channel
以及一个用于初始化的 initialize 函数:
class network_stack {
public:
virtual ~network_stack() {}
virtual server_socket listen(socket_address sa, listen_options opts) = 0;
future<connected_socket> connect(socket_address sa, socket_address = {}, transport proto = transport::TCP);
virtual ::seastar::socket socket() = 0;
virtual net::udp_channel make_udp_channel(const socket_address& = {}) = 0;
virtual future<> initialize() {
return make_ready_future();
}
virtual bool has_per_core_namespace() = 0;
virtual bool supports_ipv6() const {
return false;
}
virtual std::vector<network_interface> network_interfaces();
};reactor 中保存着一个 _network_stack,
所有的网络操作入口操作都通过其发起:
server_socket listen(socket_address sa) {
return engine().listen(sa);
}
server_socket listen(socket_address sa, listen_options opts) {
return engine().listen(sa, opts);
}
future<connected_socket> connect(socket_address sa) {
return engine().connect(sa);
}
future<connected_socket> connect(socket_address sa, socket_address local, transport proto = transport::TCP) {
return engine().connect(sa, local, proto);
}
socket make_socket() {
return engine().net().socket();
}
net::udp_channel make_udp_channel() {
return engine().net().make_udp_channel();
}
net::udp_channel make_udp_channel(const socket_address& local) {
return engine().net().make_udp_channel(local);
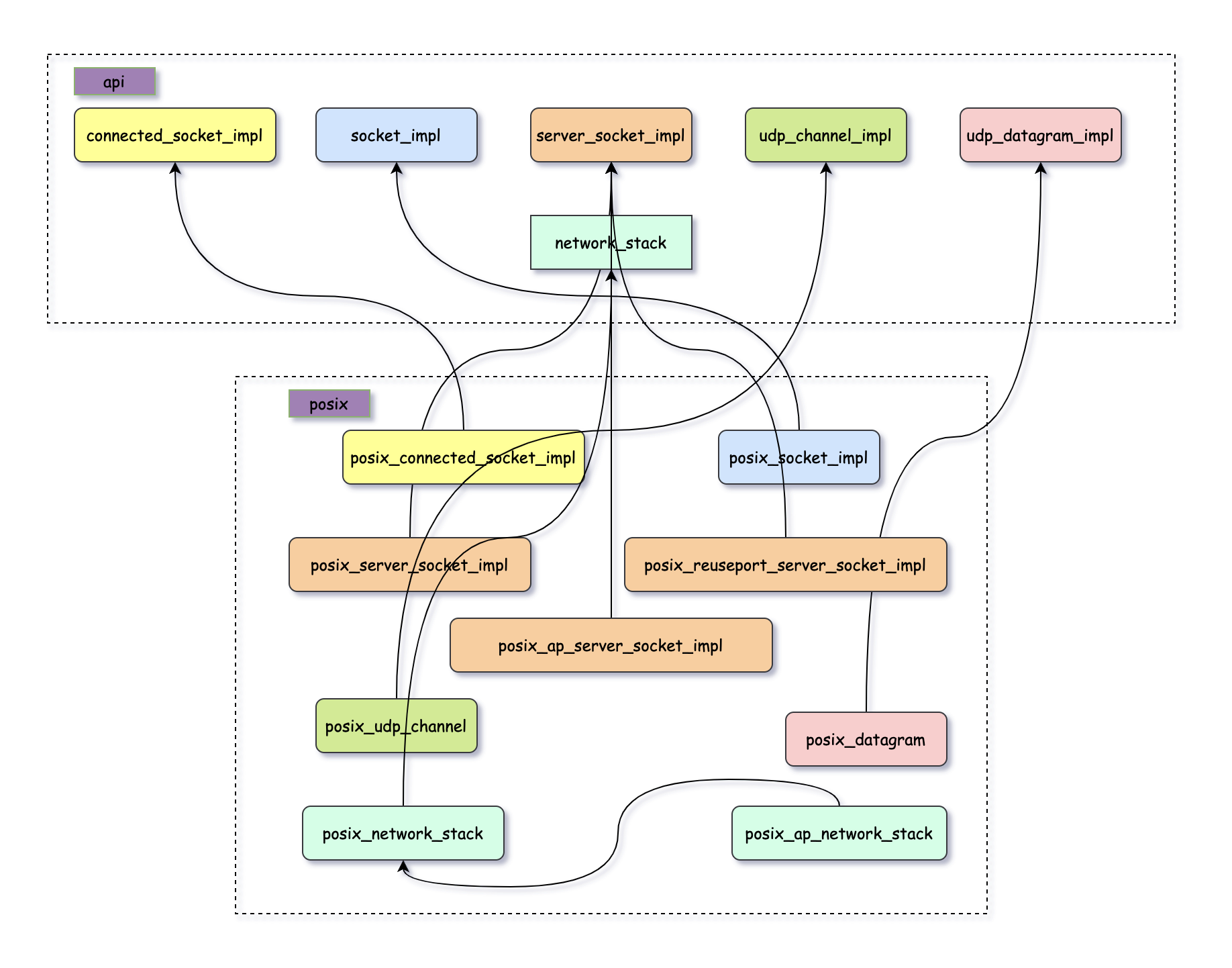
}为了加速编译, seastar 用的都是常见的 pImpl idiom, 而为了统一 native stack 与 posix stack, 则使用了接口+继承的方式;
对于 posix stack, 有如下继承体系:
大多数都是一一对应的, 但 server_socket 在 posix stack
中却有三种, 连带着 network stack 都有两种, 不过它们在 seastar app
中并不是非此即彼, 而是需要配合混合使用的; 总之,
其中的原因和实现感觉还是比较有意思的
network_stack首先看看 posix network stack 的注册:
network_stack_entry register_posix_stack() {
return network_stack_entry{
"posix", std::make_unique<program_options::option_group>(nullptr, "Posix"),
[](const program_options::option_group& ops) {
return smp::main_thread() ? posix_network_stack::create(ops)
: posix_ap_network_stack::create(ops);
},
true};
}如果是 main thread(也就是 CPU0), 那么注册的是
posix_network_stack, 否则对于其他 worker 线程, 注册的是
posix_ap_network_stack
class posix_network_stack : public network_stack {
private:
const bool _reuseport;
protected:
std::pmr::polymorphic_allocator<char>* _allocator;
public:
...
};
class posix_ap_network_stack : public posix_network_stack {
private:
const bool _reuseport;
public:
posix_ap_network_stack(const program_options::option_group& opts, std::pmr::polymorphic_allocator<char>* allocator=memory::malloc_allocator);
virtual server_socket listen(socket_address sa, listen_options opts) override;
static future<std::unique_ptr<network_stack>> create(const program_options::option_group& opts, std::pmr::polymorphic_allocator<char>* allocator=memory::malloc_allocator) {
return make_ready_future<std::unique_ptr<network_stack>>(std::unique_ptr<network_stack>(new posix_ap_network_stack(opts, allocator)));
}
};可以看出来 posix_ap_network_stack 其实就是
posix_network_stack, 只不过重写了其监听端口的逻辑,
而这个区别又来自于 reuseport 功能, 所以其实还是这个选项带来的影响,
但是需要注意的是, 这里的 reuseport 并不是值是否为 fd 设置了
SO_REUSEPORT 选项, 而是指当前内核是否支持
SO_REUSEPORT 功能(毕竟创建 posix_network_stack
的时候还没有 fd 呢)
创建 posix_network_stack 的时候会通过
reactor::_reuseport 初始化 _reuseport
字段(P.S. 为啥这个字段不直接在 posix_network_stack
里面设置为 protected 让 posix_ap_network_stack
也可以使用, 反而要放两份?), 该功能会在创建 reactor 的时候进行探测:
bool
reactor::posix_reuseport_detect() {
return false; // FIXME: reuseport currently leads to heavy load imbalance. Until we fix that, just
// disable it unconditionally.
try {
file_desc fd = file_desc::socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK | SOCK_CLOEXEC, 0);
fd.setsockopt(SOL_SOCKET, SO_REUSEPORT, 1);
return true;
} catch(std::system_error& e) {
return false;
}
}可以看到这个功能已经被强制关闭了, 理由是内核的负载均衡算法效果并不理想, 不过距离该 commit 已经过去 7 年了, 不知道内核有没有优化, 后面可以去了解下.
比较一下二者的 listen 方法, 发现只有在
!_reuseport 的情况下才有所不同,
posix_network_stack_impl 创建的是
posix_server_socket_impl, 而
posix_ap_network_stack_impl 创建的则是
posix_ap_server_socket_impl, 倒是一脉相承:
// posix_network_stack_impl
return _reuseport ?
server_socket(std::make_unique<posix_reuseport_server_socket_impl>(protocol, sa, engine().posix_listen(sa, opt), _allocator))
:
server_socket(std::make_unique<posix_server_socket_impl>(protocol, sa, engine().posix_listen(sa, opt), opt.lba, opt.fixed_cpu, _allocator));
// posix_ap_network_stack_impl
return _reuseport ?
server_socket(std::make_unique<posix_reuseport_server_socket_impl>(protocol, sa, engine().posix_listen(sa, opt), _allocator))
:
server_socket(std::make_unique<posix_ap_server_socket_impl>(protocol, sa, _allocator));所以就先来看看 posix network stack 中的 server_socket
实现
server_socket与 socket(或者说 client socket)相对应的是
server_socket, posix network stack 提供了 3 种
server_socket, 之所以有这么多, 还是考虑到负载均衡,
经过前面的 posix network stack, 我们知道:
如果当前内核支持 reuseport 功能, 那么此时所有监听描述符都会设置
SO_REUSEPORT 属性, 也就是说由内核负责负载均衡,
所以会直接在调用 reactor::listen 的线程上为该监听端口创建
posix_reuseport_server_socket_impl
否则的话, 则由 seastar 自己负责负载均衡, 那么这个时候:
posix_server_socket_impl
负责监听端口并将连接分发至其余工作线程posix_ap_server_socket_impl,
它不负责监听端口, 只需要直接拿 CPU0 分发过来的连接请求即可class posix_reuseport_server_socket_impl : public server_socket_impl {
socket_address _sa;
int _protocol;
pollable_fd _lfd;
std::pmr::polymorphic_allocator<char>* _allocator;
};
class posix_server_socket_impl : public server_socket_impl {
socket_address _sa;
int _protocol;
pollable_fd _lfd;
conntrack _conntrack;
server_socket::load_balancing_algorithm _lba;
shard_id _fixed_cpu;
std::pmr::polymorphic_allocator<char>* _allocator;
};
class posix_ap_server_socket_impl : public server_socket_impl {
using protocol_and_socket_address = std::tuple<int, socket_address>;
struct connection {
pollable_fd fd;
socket_address addr;
conntrack::handle connection_tracking_handle;
connection(pollable_fd xfd, socket_address xaddr, conntrack::handle cth) : fd(std::move(xfd)), addr(xaddr), connection_tracking_handle(std::move(cth)) {}
};
using sockets_map_t = std::unordered_map<protocol_and_socket_address, promise<accept_result>>;
using conn_map_t = std::unordered_multimap<protocol_and_socket_address, connection>;
static thread_local sockets_map_t sockets;
static thread_local conn_map_t conn_q;
int _protocol;
socket_address _sa;
std::pmr::polymorphic_allocator<char>* _allocator;
};posix_reuseport_server_socket_impl 是最简单的结构;
相比于它, posix_server_socket_impl
多了一些用于实现负载均衡的字段(其实是用户存储负载均衡算法所需要的状态信息);
而 posix_ap_server_socket_impl
相比于前面两个则显得有些奇怪, 它其实是 accept
请求和结果的聚集、分发之地, 并不直接调用 accept(2)
获取新连接, 而需要和 posix_server_socket_impl 配合使用
在行为上, 这几种 server_socket 最大的区别就在于它们
accept 新连接时的行为, 下面来逐个看看
posix_reuseport_server_socket_implfuture<accept_result>
posix_reuseport_server_socket_impl::accept() {
return _lfd.accept().then([allocator = _allocator, protocol = _protocol] (std::tuple<pollable_fd, socket_address> fd_sa) {
auto& fd = std::get<0>(fd_sa);
auto& sa = std::get<1>(fd_sa);
std::unique_ptr<connected_socket_impl> csi(
new posix_connected_socket_impl(sa.family(), protocol, std::move(fd), allocator));
return make_ready_future<accept_result>(
accept_result{connected_socket(std::move(csi)), sa});
});
}中规中矩, 其实就是调用底层 pollable_fd 的
accept 方法并对其结果进行了一层简单的
accept_result 封装
posix_server_socket_impl
&& posix_ap_server_socket_impl前面已经提到过 posix_ap_server_socket_impl 是 accept
请求和结果的聚集、分发之地; 它并不直接调用 accept(2)
获取新连接, 而需要和 posix_server_socket_impl 配合使用,
而配合的关键就在于它的两个静态数据结构:
using sockets_map_t = std::unordered_map<protocol_and_socket_address, promise<accept_result>>;
using conn_map_t = std::unordered_multimap<protocol_and_socket_address, connection>;
static thread_local sockets_map_t sockets;
static thread_local conn_map_t conn_q;其中 sockets 用于存储 accept 的结果, conn_q
用于存储 accept 请求; 这俩 map 的 key 都是 protocol
和监听地址的组合(因为可以同时用于 TCP 和 SCTP, 所以 protocol 也得是 key
的一部分)
CPU0 的 posix_server_socket_impl 负责实际调用
accept(2) 获取新连接,
当根据负载均衡算法计算发现该连接不应该由当前线程处理, 那么会将其存储在
conn_q 中
当其他线程(posix_ap_server_socket_impl)被上游调用
accept() 方法时, 首先检查 conn_q
中对于该监听地址是否已经有由 posix_server_socket_impl
发送来的 accept 结果了, 有的话则直接使用, 否则往 sockets
中添加一个 query, 当有结果发来时会先满足这些 query:
代码太多但是并不难理解所以就不贴了, 具体的写作流程如下图所示(假设用了 4 个 CPU 核):
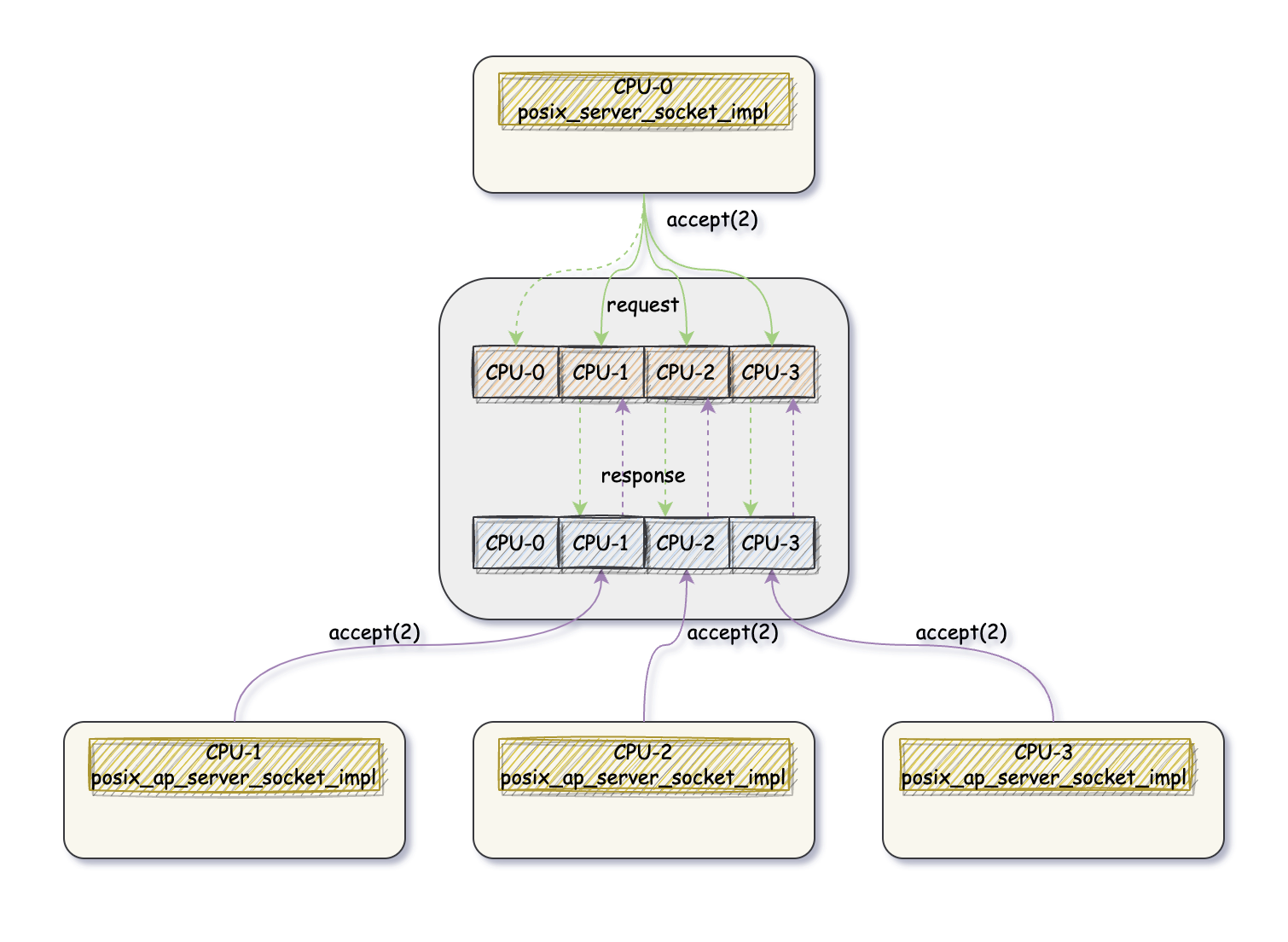
CPU-0 accept(2) 获取新连接后首先满足 request,
如果没有 pending 状态的 request, 则将该结果存起来(通过
submit_to 让该连接所属 CPU 来执行
posix_ap_server_socket_impl::move_connected_socket(),
从而可以将这个连接放到所属线程专属的本地存储中去,
图里面用多个方块表示各个线程的本地存储)
CPU-n 首先满足从 response 中查找, 找不到则注册一个 query/request(以 future/promise 的方式) 等待 CPU-0
目前 posix network stack 为非 reuseport 的 accept 提供了 3 种负载均衡策略:
enum class load_balancing_algorithm {
connection_distribution,
port,
fixed,
default_ = connection_distribution
};connnection_distribution:
该策略会将连接均匀地分发到这个 shard 去, 具体的分发策略很简单:
就是选当前正在服务的连接数最少的 shard(所以必须维护每个 shard
正在服务的连接数的状态)port: 根据 remote peer 的 port 来分发, 具体策略就是对
peer port 取模(模当前总 shard 数), 得到的结果即为该连接所属的 shard;
这样的好处是倘若 client 知道我们用了多少个 shard, 那么它总是可以通过选择
local port 来连接到同一个 shardfixed: 即将该监听端口收到的所有连接都交由某个固定的
shard 去处理这些策略都是 per server-socket 维度的: 在调用
network_stack::listen 时可以提供一个
listen_options, 其中就可以指定该监听端口的负载均衡策略,
默认使用的是 connection_distribution 策略:
struct listen_options {
bool reuse_address = false;
server_socket::load_balancing_algorithm lba = server_socket::load_balancing_algorithm::default_;
transport proto = transport::TCP;
int listen_backlog = 100;
unsigned fixed_cpu = 0u;
void set_fixed_cpu(unsigned cpu) {
lba = server_socket::load_balancing_algorithm::fixed;
fixed_cpu = cpu;
}
};socketclass posix_socket_impl final : public socket_impl {
pollable_fd _fd;
std::pmr::polymorphic_allocator<char>* _allocator;
bool _reuseaddr = false;
}连接对端:
virtual future<connected_socket> connect(socket_address sa, socket_address local, transport proto = transport::TCP) override {
if (sa.is_af_unix()) {
return connect_unix_domain(sa, local);
}
return find_port_and_connect(sa, local, proto).then([this, sa, proto, allocator = _allocator] () mutable {
std::unique_ptr<connected_socket_impl> csi;
csi.reset(new posix_connected_socket_impl(sa.family(), static_cast<int>(proto), _fd, allocator));
return make_ready_future<connected_socket>(connected_socket(std::move(csi)));
});
}对于 TCP 调用的则是 find_port_and_connect,
并没有直接调用 reactor::posix_connect : 一条 TCP
连接由一个四元组标识, 但是通常我们 connect(2) 时会指定本机
IP(可能是 wildcard)以及对端的 IP 和 port, 但是不会主动设置本机的 port,
此时会由 OS 帮助选择一个可用的 port, 但是选择的策略可能并不是我们需要的,
这里 find_port_and_connect 就是帮助选择一个可用的本机
port(调用方没有指定的话), 期望这样能够有利于 server 的负载均衡:
If local address provided to connect() has wildcard port try to use a port number that satisfy equation: port modulo number_of_shards = current_shard. If a server uses port based load balancing and has the same amount of shards as a client it will result in connection going to the same shard number in the server, otherwise no harm will be done. Connecting to the same shard number is beneficial for applications that distribute work based on a hash of the data been processed since in such systems this will eliminate internal cross-cpu hop from the pipeline.
实现方面则很简单:
errno 为 EADDRINUSE 或者
EADDRNOTAVAIL, 说明这个 port 可能正被占用着, 继续随机下一个
port 尝试连接connected_socketclass posix_connected_socket_impl final : public connected_socket_impl {
pollable_fd _fd;
const posix_connected_socket_operations* _ops;
conntrack::handle _handle;
std::pmr::polymorphic_allocator<char>* _allocator;
...
};posix_connected_socket_impl 需要处理 unix socket、TCP
以及 SCTP, 所以抽象了一个 posix_connected_socket_operations
表示 socket 操作的接口, 各个 protocol 通过继承实现自己的一套接口
_handle 则是用于 server_socket
实现负载均衡策略, 其中需要维护各个 shard 正在处理的连接的状态信息
对于 connected_socket, 最重要的操作就是读、写
socket,按照 seastar 的一贯传统, 它并不直接提供 read/write 方法,
而是将其抽象成 data source 和 data sink,
从而方便和其他现有组件组合使用:
virtual data_source posix_connected_socket_impl::source() override {
return source(connected_socket_input_stream_config());
}
virtual data_source posix_connected_socket_impl::source(connected_socket_input_stream_config csisc) override {
return data_source(std::make_unique<posix_data_source_impl>(_fd, csisc, _allocator));
}
virtual data_sink posix_connected_socket_impl::sink() override {
return data_sink(std::make_unique<posix_data_sink_impl>(_fd));
}在 data_source_impl 和 data_sinke_impl
的基础上实现了 posix_data_source_impl 和
posix_data_sink_impl:
class posix_data_source_impl final : public data_source_impl, private internal::buffer_allocator {
std::pmr::polymorphic_allocator<char>* _buffer_allocator;
pollable_fd _fd;
connected_socket_input_stream_config _config;
};
class posix_data_sink_impl : public data_sink_impl {
pollable_fd _fd;
packet _p;
};最终我们通过 data_source 和 data_sink
接口去处理数据读写
TODO: